LÖVE (Love2D) 入門編:9.日本語を1文字ずつ表示する
(2018.7.25. 公開) (2018.8.26. 対象をバージョン 11 系列に変更)
ゲームのオープニングとかで、文章が1文字ずつ表示されていくやつ、あるじゃないですか。ああいうの、やってみましょうか。
まず、文章を用意します。文字列の配列にします。内容に意味はありませんので悪しからず。
message = {
"いにしえの時、",
"深い森に囲まれた小さな国があった。",
"かつてこの国は賢者に率いられ、",
"人々は貧しくも平和に暮らしていたが、",
"賢者なきあとは争いが絶えず",
"不安におびえる年月が続いた。"
}
1. 文字列から1文字ずつ取り出す
Lua/LuaJIT の標準機能では、文字列の一部分は string.sub(s, i, j) で取り出すことができるが、この関数は日本語文字列に対応していない。幸い、LÖVE では utf8 というモジュールが使える。このモジュールを使うためには、プログラムの先頭に次の一行を置く。
local utf8 = require("utf8")
UTF-8 エンコーディングで書かれた日本語文字列は、下のようになっている。UTF-8 コード(1つ1バイト)が3つずつ組になってひらがな1文字を表現しているのがわかる。
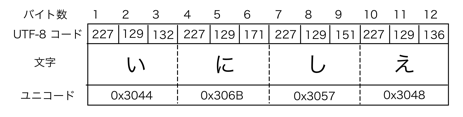
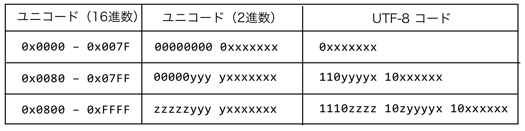
「ユニコード」とは、国際標準規格で定められた文字の符号(数値)である。UTF-8 は、ユニコードの数値を一定規則に従ってバイト列に変換したものである(下図)。
文字列から UTF-8 文字を1つずつ取り出すために、utf8.codes(s) という関数がある。この関数は、一般型 for 文と組み合わせて、次のように使う。
for pos, code in utf8.codes(s) do
ブロック -- pos が先頭からのバイト数、code が1文字ぶんのユニコード
end
code はユニコードで、これは数値であるから、表示するためには文字列に戻さなくてはならない。そのためには、utf8.char(code) という関数が使える。この関数は、ユニコードを受け取り、それを UTF-8 文字列に変換して返す。
for pos, code in utf8.codes("いにしえ") do
print(pos, utf8.char(code))
end
--【出力】
1 い
4 に
7 し
10 え
UTF-8 文字列に含まれる文字数を得るには、utf8.len(s) が使える。また、文字列の一部分を取り出したいときは、utf8.offset(s, n, i) という関数が使える。この関数は、「文字列 s の n 番目の文字の始まるバイト位置」を返す。i が指定されている場合は、i 番目のバイトから数えて n 番目の文字を探す。
s = "いにしえ"
utf8.offset(s, 1) -- 1(1文字目=「い」のバイト位置)
utf8.offset(s, 2) -- 4(2文字目=「に」のバイト位置)
utf8.offset(s, 3) -- 7(3文字目=「し」のバイト位置)
utf8.offset(s, 2, 4) -- 7(4バイト目から数えて2文字目=「し」のバイト位置)
2. 文字列を表示するサイズを計算する
文字を1つずつ表示するとき、それぞれの文字の幅がわかっていないと、文字が間延びしたり、重なったりしてしまう。ひらがなや漢字はすべて同じ幅であることが多いが、半角文字が混じってくるとそうとも限らなくなる。文字の幅の情報はフォントごとに決まっているので、前ページで述べた「フォントオブジェクト」に問い合わせれば、文字の幅がわかる。具体的には、Font:getWidth(s) というメソッドを使う。
説明の中に出てくる タイプ名:メソッド名 という記述は、「そのタイプのオブジェクトが共通して持っているメソッド」を示すものとする。プログラム中で実際に使うときには、タイプ名 のところを、そのタイプのオブジェクトに置き換える必要がある。
f = love.graphics.newFont("ipag.ttf", 24) -- IPAゴシック、24ポイントのフォント
w = f:getWidth("い") -- 「い」という文字の幅を求める
getWidth は「フォントオブジェクト」f が持つメソッドである。メソッド呼び出しなので、f と getWidth の間はコロン : であることに注意。間違えて f.getWidth("い") とピリオド . にすると、下のようなエラーが出る。
Error
main.lua:15:bad argument #1 to 'getWidth' (Font expected, got string)
言語編の「メソッド」のところに書いた通り、コロンを使って f:getWidth("い") と書くと、一番目の引数として f が自動的に挿入される。つまり、f:getWidth("い") は f.getWidth(f, "い") と同じ意味になる。コロンの代わりにピリオドを使って f.getWidth("い") と書いてしまうと、"い" が第一引数と解釈されてしまうため、上のように「第一引数は Font 型でないといけないのに文字列型になってるよ」というエラーが出てしまうのである。
次のプログラムでは、「いにしえ」という文字列を1文字ずつ表示する。1文字表示するごとに、表示する x 座標を文字の幅分だけ増加させている。
-- サンプルプログラム 9-01 main.lua
-- ipag.ttf (IPAゴシックフォント) が必要
local utf8 = require("utf8")
function love.load()
love.graphics.setBackgroundColor(0, 0, 0) -- 背景を白にする
love.graphics.setColor(0, 0, 0) -- 文字色を黒にする
font = love.graphics.newFont("ipag.ttf", 24) -- 24ポイントのフォントを作る
love.graphics.setFont(font) -- そのフォントを設定
st = love.timer.getTime() -- 開始時刻を記録
end
function love.draw()
s = "いにしえ"
m = (love.timer.getTime() - st) / 0.2 -- 表示する文字数(経過時間÷0.2秒)
x = 0 -- 表示する x 座標
i = 1 -- 何文字目か
for pos, code in utf8.codes(s) do
if i > m then break end -- 表示する文字数を超過していれば終了
local ss = utf8.char(code) -- 文字を1つずつ取り出す
love.graphics.print(ss, x, 0) -- 表示
x = x + font:getWidth(ss) -- 文字の幅だけ右にずらす
i = i + 1 -- 忘れないように!
end
end
love.draw() の中では、毎回全部の文字を書き直さないといけないことに注意。Love2d では、ゲームの画面更新が簡単にできるように、love.draw() を呼ぶ直前に画面を背景色で塗りつぶしている。したがって、「前に書いた文字」も含めて、すべての文字を毎回書く必要がある。
3. メッセージを1文字ずつ表示する
それでは、メッセージの表示、やってみましょう。メッセージ全体が、画面の真ん中に表示されるようにしてみた。フォントは おたもん さん作の「源暎ラテミン」を使いました。このフォントは SIL Open Font ライセンスの元で配布されており、無償であれば再配布が可能。こちらに置いておきます → GenEiLatin_v2.zip
-- サンプルプログラム 9-02 main.lua
-- GenEiLateMin_v2.ttf (「源暎ラテミン」フォント) が必要
local utf8 = require("utf8")
function love.load()
message = {
"いにしえの時、",
"深い森に囲まれた小さな国があった。",
"かつてこの国は賢者に率いられ、",
"人々は貧しくも平和に暮らしていたが、",
"賢者なきあとは争いが絶えず",
"不安におびえる年月が続いた。"
}
love.graphics.setBackgroundColor(0.55, 0.70, 0.05) -- 背景を緑にする
love.graphics.setColor(1, 1, 1) -- 文字色を白にする
font = love.graphics.newFont("GenEiLateMin_v2.ttf", 32) -- 32ポイントのフォントを作る
love.graphics.setFont(font) -- そのフォントを設定
width = love.graphics.getWidth() -- 現在の画面の横幅
height = love.graphics.getHeight() -- 現在の画面の高さ
lines = #message -- メッセージの行数
h = math.floor(height / (lines + 2)) -- 1行の高さ(上下を1行ずつ空ける)
st = love.timer.getTime() -- 開始時刻を記録
end
function love.draw()
m = (love.timer.getTime() - st) / 0.2 -- 表示する文字数(経過時間÷0.2秒)
y = h -- 表示する y 座標
i = 1 -- 何文字目か
for j, s in ipairs(message) do -- message を順に処理
x = math.floor((width - font:getWidth(s)) / 2) -- 文字を表示する位置
for pos, code in utf8.codes(s) do
if i > m then break end -- 表示する文字数を超過していれば終了
local ss = utf8.char(code) -- 文字を1つずつ取り出す
love.graphics.print(ss, x, y) -- 表示
x = x + font:getWidth(ss) -- 文字の幅だけ右にずらす
i = i + 1 -- 忘れないように!
end
y = y + h -- 行の高さだけ下にずらす
i = i + 2 -- 行ごとに間を置く(2文字ぶん)
end
end
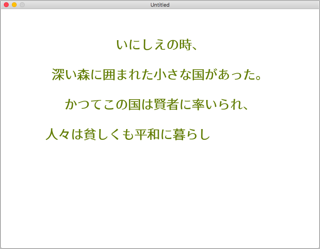
(※ 見やすくするため色を反転しています)